
RL入门
- DQN作为强化学习领域第二基本的算法(第一是Q_Learning)其最适用于(连续状态空间,离散动作空间),其本质和Q学习是完全一致的
DQN强化学习基本框架
不管强化学习之后怎么优化,其最基本的概念都如下:
(1)动作价值函数(Q函数)::该函数表示在策略下,在这个状态动作之下得到的期望累计回报。
- 在DQN离散动作域的的范围之下,输入为n维状态张量,输出为n维动作张量,那么如何得到Q值呢?**(Q值为1维标量)**那当然是选择Q值更大的离散动作对应的Q值,这相当于选取了更高概率的动作作为奖励估计
q_values = self.policy_net(state_batch).gather(dim=1, index=action_batch)
与之相对应的还有状态价值函数:其代表的意义为在该策略的情况下该状态得到的期望累计回报,用公式表达其与动作价值函数的关系为:
也就是表示在每个动作的Q值的加权平均,但是在DQN网络中,我们是按照动作价值函数进行策略估计,故而可以得到 (贝尔曼最优方程):
- 在DQN连续动作域的范围下(DQN其实已经进化为DDPG),MLP的输入将变成,输出将变成控制量的个数,使用现代控制理论来比喻的化,输入为,输出为,对于DDPG我将后续在进行叙述
(2)策略:这个即是我们强化学习需要训练的东西,在DQN学习网络中,我们训练的多层感知机器MLP中的参数就对应这个策略。
(3)策略迭代:策略迭代由两个部分组成,策略评估和策略改进,这两个环节是相互闭环且收敛的状态,如下图所示:
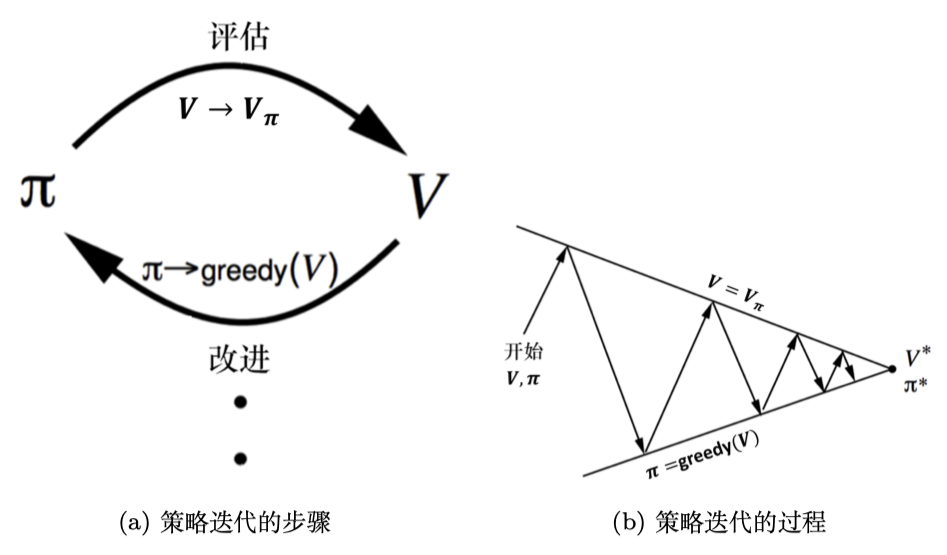
-
策略评估:根据当前的策略即(MLP网络),对智能体进行一个预测得到一个价值函数,在DQN中即为上文所说的
-
策略改进:计算在这一步智能体的期望Q值:
在DQN网络中,将期望的Q值与策略评估中计算出的Q值进行均方根误差计算,然后再根据误差反向传播以更新MLP网络,从而使训练出来的模型更加收敛实际情况。
(4)价值迭代:直白来说,价值迭代就是直接使用贝尔曼最优方程进行迭代,从而寻找最佳的价值函数 …
在这里介绍和总结其中一种经典的框架并列举其框架各个部分常用的算法
- 策略的迭代